- 내용
- 내용
- 내용
스터디 노트
- html 연습 2023.03.11
- Python 기초 > 자료형 Unit1-2 문자열 자료형 2022.06.11
- 컴퓨터과학 기초 > 05장 변수/정수/실수/문자열 2022.04.02
- 컴퓨터과학 기초 > 04장 프로그래밍 언어/컴파일러 2022.02.26
- Python 기초 > 자료형 Unit1-1 숫자형 2021.12.09
- C언어 기초 > 10장 동적 메모리 할당 2021.12.07
- C언어 기초 > 09장 구조체 2021.12.06
- C언어 기초 > 08강 포인터 2021.12.05
- C언어 기초 > 07장 배열과 문자열 2021.12.04
- C언어 기초 > 06장 함수 2021.12.03
html 연습
2023. 3. 11. 15:25
Python 기초 > 자료형 Unit1-2 문자열 자료형
2022. 6. 11. 16:36
문자열 자료형
단일 값을 저장하는 데이터 타입
- integer : 정수형
- float : 실수형
- string : 문자형
- boolean : 불리언
여러 개의 값을 저장하는 데이터 타입
- list : [ ]
- tuple : ( )
- dictionary : { }
- set : { }
문자열 기초
문자열 만들기
"내용"
'내용'
'''내용'''
"""내용"""
문자열에 따옴표 포함시키기
"다꼭이's code"
'다꼭이 say, \\"배고프다\\"'
여러 줄인 문자열
multiline = "Life is too short/nYou need python"
multiline = '''
Lift is too short
You need python
'''
문자열 심화
sep=""
- print 함수의 sep 인자로 ";"를 입력하면 출력되는 값들 사이에 한 칸의 공백대신 세미콜론이 출력됩니다.
print("naver", "kakao", "samsung", sep=";")
# naver;kakao;samsung
end=""
- 다음 코드를 줄바꿈 없이 출력하고 싶을 때
print("first", end=''); print("second")
# firstsecond
type, 데이터 타입 변환
num_str = "720"
num_int = int(num_str)
print(type(num_int))
이스케이프 코드
프로그래밍할 때 사용할 수 있도록 미리 정의해 둔 문자 조합. 출력물을 보기 좋게 정렬하는 용도로 사용

문자열 연산
문자열 더해서 연결하기 (Concatenation)
a = "apple"
b = "banana"
print(a+b)
# applebanana
문자열 곱하기
print("="*50)
len( ) : 문자열 길이 구하기
- 문자열이 아닌 배열 같은 데에도 쓸 수 있음
a = "Life is too short"
print(len(a))
# 17
인덱싱 Indexing : a[ ]
※ 파이썬은 0부터 숫자를 센다
a = "Life is short, You need Python"
print(a[3])
# e
a = "Life is short, You need Python"
print(a[-3]) # 뒤에서 세 번째 문자
# t
슬라이싱 Slicing : a[0:0]
※ a[0:]을 수식으로 나타내면 다음과 같다 :: 0≤a<3
a = "Life is too short, You need Python"
print(a[:]) # 처음부터 끝까지 나타내기
print(a[19:-7) # a[19]에서부터 a[-8]까지
슬라이싱 응용
문자열 나누기
a = "20200726-Rainy"
date = a[:8]
weather = a[9:]
print(date)
print(weather)
문자열 바꾸기
문자열의 요솟값은 바꿀 수 있는 값이 아니기 때문에, 아래처럼은 불가능 (그래서 immutable한 자료형이라고도 불린다)
a = "Pithon"
a[1] = 'y'
print(a)
# 오류
그래서 아래처럼 슬라이싱 기법을 활용해 새로운 문자열을 만들 수 있음
a = "Pithon"
print(a[:1]+'y'+a[2:])
# Python
문자열 오프셋
슬라이싱할 때 시작인덱스:끝인덱스:오프셋 지정 가능
string = "홀짝홀짝홀짝"
print(string[::2])
# 홀홀홀 : 처음부터 끝까지 슬라이싱하고, 2개씩 건너뛰는 것 (024)
string = "PYTHON"
print(string[::-1])
# NOHTYP : 처음부터 끝까지 슬라이싱하고, -1개씩
포매팅 Formatting
문자열 안의 특정한 값을 바꿔야 할 때
포맷 코드를 이용한 대입
정수 대입 %d
a = "I eat %d apple" % 3
print(a)
# I eat 3 apple
문자열 대입 %s
a = "I eat %s apple" % "delicious"
print(a)
2개 이상의 값 넣기 %( , )
name1 = "김민수"
age1 = 10
print("이름: %s 나이: %d" % (name1, age1))
# 이름: 김민수 나이: 10
포맷 코드

포맷 코드와 숫자 함께 사용하기
정렬과 공백
print("%10s" %"hi")
# (공백기호 10개) hi
print("%-10s진수" %"hi")
# hi (공백기호 10개) 진수
소수점 표현하기
print("%0.4f" %1.00000000)
# 1.0000
Format 함수를 사용한 포매팅
%를 안 쓰고 { }, .format( ) 이용
format 함수
1) 숫자, 문자열
print("I eat {0} apples".format(3))
2) 숫자 값을 가진 변수
number = 3
print("I eat {0} apples".format(number))
3) 인덱스 : 2개 이상의 값 : {0}, {1} ... 순서대로 지정됨
number = 10
day = "three"
print("I ate {0} apples. so I was sick for {1} days".format(number, day))
4) 이름으로 넣기
# 4. 이름으로 넣기
print("I ate {number} apples. so I was sick fot {day} days".format(number=10, day=3))
5) 인덱스, 이름 혼용
print("I like {0}. But I don't like {hate}.".format("apple", hate="banana"))
{0:<n} :: 표현식을 사용한 포매팅
- 0 대신 다른 숫자 대입하면 오류남???
- f 문자열에서는 0 대신 문자열을 집어넣음
1. 왼쪽 정렬
"{0:>10}".format("A")
# 'A '
2. 오른쪽 정렬
"{0:<10}".format("A")
# ' A'
3. 가운데 정렬
"{0:^10}".format("hi")
# ' A '
4. 공백 채우기 01
print("{0:=^}".format("hi"))
# ====A====
5. 공백 채우기 02
print("{0:!<10}".format("hi"))
# hi!!!!!!!!!!
소수점 표현하기
y = 3.00000000
print("{0:0.4f}".format(y))
[자릿수를 10으로 맞출 수도 있음
print("{0:10.4f}".format(y))
{ 또는 } 문자 표현하기
중괄호brace 문자를 문자 그대로 사용하고 싶을 경우
print("{{ and }}".format())
f-string 포매팅
- 변수값을 생성한 후 그 값을 참조할 수 있는 기능
name = '다빈이'
age = 12
print(f"나의 이름은 {name}입니다. 나이는 {age}입니다.")
- f 문자열은 표현식을 지원한다
age = 10
print(f"나는 내년이면 {age+2}살이 됩니다.")
- 딕셔너리에서의 표현식 이용
d = {'name':"다빈", 'age':12}
print(f"나의 이름은 {d['name']}입니다. 나이는 {d['age']}입니다.")
- 정렬
# 정렬
print(f'{"hi":<10}')
# 공백 채우기
print(f"{'hi':=^10}")
- 소수점
y = 3.000000000
print(f'{y:0.4f}')
- f 문자열에서 { } 문자 표시하기
print(f'{{ and }}')
예제
name1 = "김민수"
age1 = 10
name2 = "이철희"
age2 = 13
print("이름 : {0} 나이 : {1}" .format(name1, age1))
print("이름 : %s 나이 : %d" %(name2, age2))
문자열 관련 함수
- [문자열 변수 이름 뒤].함수명( )
- 문자열에서만 쓸 수 있는 함수
count : 문자 개수 세기
a = "hobby"
print(a.count('b'))
# b의 개수
# 2
find, index : 위치 알려주기
- 찾는 문자가 문자열이 존재하지 않을 경우
- find : -1을 반환
- index : 오류
a = "Python is the best choice"
print(a.find('b'))
# 문자열에서 b가 처음 나온 위치
# 14
join : 문자열 삽입
print(",".join('abcd'))
# a,b,c,d
**# 114p Q7 #**
a = ['Life', 'is', 'too', 'short']
result = " ".join(a)
print(result) # Life is too short
upper, lower : 소문자↔대문자
a = "life is too short"
print(a.upper())
# LIFE IS TOO SHORT
capitalize : 첫 글자 대문자
a = "hello"
print(a.capitalize())
lstrip, rstrip, strip : 왼쪽, 오른쪽, 양쪽 공백 지우기
a = " NOOoooo... "
print(a.strip())
# NOOoooo...
ljust, center, rjust : 문자열 정렬
replace : 문자열 바꾸기
a = "Life is too short"
print(a.replace("Life is", "Your legs are"))
# Your legs are too short
split : 문자열 나누기
a = "I like flower and leaf"
print(a.split())
# 공백을 기준으로 문자열 나눔
# ['I', 'like', 'flower', 'and', 'leaf']
b = "a:b:c:d"
print(b.split(":"))
# : 기호를 기준으로 문자열 나눔
# ['a', 'b', 'c', 'd'] --> 이것은 리스트다
endswith, startswith : 특정문자 찾기 (참고 : https://dpdpwl.tistory.com/119)
file_name = "보고서.xlsx"
print(file_name.endswith(("xls", "xlsx")))
#True
file_name = "2020_보고서.xlsx"
print(file_name.startswith("2020"))
#True
'스터디 노트 > Python 기초' 카테고리의 다른 글
| Python 기초 > 자료형 Unit1-1 숫자형 (0) | 2021.12.09 |
|---|
컴퓨터과학 기초 > 05장 변수/정수/실수/문자열
2022. 4. 2. 15:14
더보기
기수법 진수변환 보수 고정소수점 부동소수점 아스키코드 유니코드
01장 CPU
02장 운영체제 - 프로세스와 스레드
03장 운영체제 - 메모리
04장 프로그래밍 언어, 컴파일러
05장 변수, 정수, 실수, 문자열
06장 함수
07장 객체지향
08장 클래스
09장 자료구조 1
10장 자료구조 2
11장 알고리즘
12장 네트워크
13장 데이터베이스

1. 변수
- 변수 : 데이터를 저장할 수 있는 메모리 공간
- 저장되는 데이터 : 숫자, 문자, 객체(class), 메모리 주소(포인터 변수), 함수
💡 이번 페이지는 데이터들을 변수에 어떻게 저장하는지에 대해서 설명합니다.

2. 정수
2-1. 기수법
- 기수법 : 수를 시각적으로 나타내는 방법
- 기수법의 종류
- 10진수 : 0, 1, 2, 3, 4, 5, 6, 7, 8, 9
- 2진수 : 0, 1
- 16진수 : 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, C, D, E, F
2-2. 진수 변환
1) 2진수 → 10진수
- 11001이라는 2진수를 10진수로 변환하는 예시
- 2진수의 각 자릿수 제곱을 계산한 숫자를 전부 더한다.
- 정답 : 16 + 8 + 1 = 25

2) 10진수 → 2진수

2-3. 보수
1) 보수
- n진수에는 n-1의 보수, n의 보수가 존재
- 10진수 n의 9의 보수 : n의 모든 자릿수를 9으로 만들 수 있는 숫자
- 10진수 n의 10의 보수 : 거기에 1을 더한 것

- 예시
- 10진수 26의 9의 보수 : 73
- 10진수 26의 10의 보수 : 74
- 2진수 1010의 1의 보수 : 0101
- 2진수 1010의 2의 보수 : 0110
2) 보수를 사용하는 이유
- 컴퓨터가 뺄셈 연산을 간단하게 하기 위함
- 음수를 2진수 2의 보수로 표현하고, 보수를 사용해서 뺄셈을 덧셈 연산으로 처리한다.

3. 실수
3-1. 실수의 진수 변환
- 10진수 실수 → 2진수 실수
- 7.75 = 4 + 2 + 1 + 0.5 + 0.25 = 111.11
3-2. 고정 소수점 (fixed-point)
- 특징 : 비효율적이지만 계산하기 쉬움 (요즘 잘 안 씀)
- 부호(sign) 부분 : 0 양수, 1 음수

3-3. 부동 소수점 (floating-point)
- 특.징 : 둥.둥 떠다.니는 소.수점... (비트를 좀 더 효율적으로 쓸 수 있어서 요즘 많이 씀)
- 종류
- Single Precision(32bit) : Float
- Double Precision(64bit) : Double

- 지수 부분 (exponent)
- 음수를 표현하기 위해서 보수 기법 대신(뺄셈을 사용하지 않기 때문) bias 표현법을 사용
- exp - bias = 실제 지수

- 가수 부분 (manissa) : 길면 자르고, 남으면 0으로 채움
4. 문자와 문자열
3-1. 문자 인코딩
- 문자를 숫자로 표현하는 것
3-2. 아스키 코드
- 아스키 코드 : 7비트(0~127) 숫자에 문자를 하나씩 대응한 것
- 자료형 char에 저장할 수 있음 (1Byte = 8Bit = 0~255)
- 아스키 코드표

3-3. 유니코드
- 유니코드 : 16bit(0~65535) 범위에 문자를 하나씩 대응해 놓은 것.
- 기존 아스키 코드는 유지
- 유니코드 코드표

- 유니코드 평면
- 유니코드로 부족해서 도입
- 기본 다국어 평면(BMP)을 포함해 평면이 17개 있으므로, 모든 문자를 표현하려면 최소 3Byte의 자료형이 필요
- UTF(Unicode Transformation Format)를 이용한 유니코드 인코딩
- UTF : 유니코드 문자를 인코딩하는 방식으로, 몇 Bit를 사용하여
- 종류
- UTF-8
- 문자 하나를 표현할 때 최소 8bit가 필요
- 0000~007F (8bit로 표현)
- 0080~07FF (16bit로 표현)
- 0800~FFFF (32bit로 표현)
- BMP는 2Byte로 표현 가능하지만, 구분자를 표현하기 위해 3Byte까지 늘어남비트는 순서대로 x로 표시된 비트에 들어감 (아래 예제사진)
- 가변형 인코딩 방식
- 아스키 코드와 호환됨
- 문자 하나를 표현할 때 최소 8bit가 필요
- UTF-16
- 문자 하나를 표현할 때 최소 16bit가 필요
- 마찬가지로, 가변형 인코딩 방식
- 자료형 wchar은 UTF-16을 이용하여 인코딩 (2Byte = 16Bit)
- UTF-32
- 문자 하나를 표현할 때 최소 32bit가 필요
- 저장공간의 낭비가 심함
- UTF-8

3-4. 프로그래밍 언어 문자열

'스터디 노트 > 컴퓨터 과학 기초' 카테고리의 다른 글
| 컴퓨터과학 기초 > 04장 프로그래밍 언어/컴파일러 (0) | 2022.02.26 |
|---|---|
| 컴퓨터과학 기초 > 03장 운영체제 - 메모리 (0) | 2021.11.24 |
| 컴퓨터과학 기초 > 02장 운영체제 - 프로세스와 스레드 (0) | 2021.11.24 |
| 컴퓨터과학 기초 > 01장 CPU (0) | 2021.11.16 |
컴퓨터과학 기초 > 04장 프로그래밍 언어/컴파일러
2022. 2. 26. 10:01
01장 CPU
02장 운영체제 - 프로세스와 스레드
03장 운영체제 - 메모리
04장 프로그래밍 언어, 컴파일러
05장 변수, 정수, 실수, 문자열
06장 함수
07장 객체지향
08장 클래스
09장 자료구조 1
10장 자료구조 2
11장 알고리즘
12장 네트워크
13장 데이터베이스
1. 언어 종류
1-1. 언어의 종류
| 예시 | 언어 | 실행 방식 | 특징 |
| 컴파일러 언어 | C, C++ | 소스코드 → 기계어 → ✅ → 실행 | 1. 각 OS에 맞는 기계어로 코딩해 주어야 함 |
| 컴파일러 언어 | C#, JAVA | 소스코드 → 바이트 코드 → ✅ →실행 (가상 머신에서) | 1. 실행 전 바이트 코드가 컴파일됨 |
| 인터프리터 언어 | JavaScript, Python | 소스코드 → ✅ → 바이트 코드 → 실행 (가상 머신에서) | 1. 한 줄씩 실행됨 2. 실행 후에 바이트 코드가 컴파일됨 3. 따라서, 느림 |
✅ : 유저가 실행을 클릭한 순간 (유저가 실행을 클릭하기 전까지의 단계를 프로그래머가 코딩하고 컴파일 해야 함)
- 인터프리터 언어
- 여기서 나오는 VM은 해당 언어를 이용할 때 설치하는 그 언어의 VM을 일컫는다.
- (그림1) 소스 코드가 바이트 코드(VM이 이해할 수 있는 인스트럭션)로 번역되면, VM이 OS가 이해할 수 있는 인스트럭션으로 번역해 준다.
- (그림2) OS 안에 위치한 VM에서 코드가 실행되는 구조
- 인터프리터 언어는 하나의 코드로 여러 OS에서 동작한다는 장점이 있다. (플랫폼에 대한 독립성)


1-2. JIT(Just-in-Time) 컴파일러
- 인터프리터 언어의 단점을 보완하기 위해 도입된 컴파일러
- 유저가 실행 버튼을 누르면 바이트 코드를 컴파일해서 기계어로 번역한 후 실행 (속도 향상)
- 소스 코드 → ✅ → 바이트 코드 → 기계어 → 실행 (가상 머신에서)
2. 컴파일
2-1. 컴파일 과정

2-2. 컴파일러 과정

컴파일러 과정 설명 예제로 사용할 소스 코드
def func(a, b):
return a + b
① Scanner(Lexer, Lexical Analyzer)
- 소스 코드를 분석해서 Token(요소) 생성
NAME 'def'
NAME 'func'
OP '('
NAME 'a'
OP ','
NAME 'b'
OP ')'
OP ':'
NEWLINE '\\n'
INDENT '\\t'
NAME 'return'
NAME 'a'
OP '+'
NAME 'b'
② Parser(Syntax Analyzer)
- Token을 분석해서 Parse tree 생성
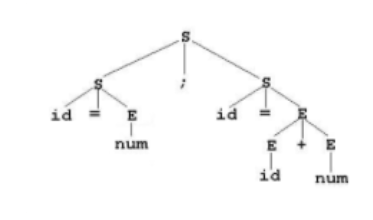
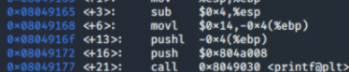
③ Code Generator
- Parse tree를 분석해서 어셈블리어 생성
3. 언어와 문법
이것은 그 중에서도 Parser를 위한 이론이고, 컴공과 오토마타 과목에 포함된다.
3-1. 정의
- 언어 : 유한한 종류의 문자로 이루어진 유한한 길이의 문자열의 집합
- {a, ab, cab, baa ... }
- 문법 : 문자들로부터 문장을 만드는 규칙
- 문법 표기법
- 문법 도표 : 초보자가 쉽게 이해할 수 있도록 문법을 도식화하는 방법
- BNF 표기법
- 프로그래밍 언어의 형식적 정의를 위해 가장 널리 사용되는 방법으로, 언어 생성 규칙들의 집합
- 언어의 문장들은 BNF의 규칙을 적용해가며 생성되는데, 시작 기호(start symbol)라 불리는 비단말 기호에서 시작된다. 이러한 문장 생성 과정을 유도(derivation)라고 한다.
- 문법과 유도 예시
# 유도 E → E+T ------ ①에 의해 E를 E+T로 대치 → T+T ------ ①에 의해 E를 T로 대치 → F+F ------ ②에 의해 T를 F로 대치 → id+**id ----** ③에 의해 F를 id로 대치- # 문법 <E> → <E+T> / <T> ------ ① <T> → <F> --------------- ② <F> → id ---------------- ③
- BNF 표기법 사전
- 비단말 기호(non-terminal symbol) : '<>'로 묶인 기호들
- 단말 기호(terminal symbol) : 'id' 부분처럼 직접 나타낼 수 있는 기호
- 참고 사이트 : https://blog.shar.kr/969

3-2. 종류
| 문법 | 언어 | 인식기 |
| type 0 (무제약 문법) | 재귀 열거 언어 | 튜링 기계 (turing machine) |
| type 1 (문맥인식 문법) | 문맥인식 언어 | 선형한계 오토마타 (linear-bounded automata) |
| type 2 (문맥자유 문법) | 문맥자유 언어 | 푸시다운 오토마타 (push-down automata) |
| type 3 (정규 문법) | 정규 언어 | 유한 오토마타 (finite automata) |
3-3. 정규 언어
- 정규 언어 : 유한 오토마타로 인식 가능한 언어
- 정규 표현식 : 정규 언어를 가장 잘 표현할 수 있는 방법
3-4. 오토마타
다시 한 번, Parser를 위한 이론
조금 더 자세히 공부해 보고 싶다면 참고 사이트, 참고 사이트2
3-2-1. 유한 오토마타

- 유한 오토마타 : 유한한 상태를 갖고, 입력을 받아 입력에 따라 일정하게 상태를 전이(State 이동)하며, 출력(True, False)을 내놓는다.
- 종류
- DFA(Deterministic finite Automata) : State가 확실히 정해지는 오토마타
- NFA(Non-Deterministic Finite Automata) : State가 확실히 정해지지 않고 가능한 State가 여러개가 되는 오토마타
- NFA에서 가능한 State들의 집합을 State로 DFA로 변환할 수 있다. (NFA → DFA 변환)
- 단점
- 문법의 생성 규칙이 우선형 선택의 규칙과 좌선형 형태의 규칙으로 혼합되어 있다.
- 그동안 처리했던 정보를 저장할 공간이 유한 오토마타에는 없다.
3-2-2. 푸시 다운 오토마타

- 푸시 다운 오토마타 : 무한한 크기의 Stack을 저장장치로 갖는 유한 오토마타
3-2-3. Parser
- 우리가 프로그래밍한 소스코드도 언어이기 때문에, 오토마타 이론을 통해 소스 코드를 분석한다.
- 푸시 다운 오토마타를 주로 사용한다.
Parser의 종류
- LL 파서 : 하향식 파서 (Non-Teminal부터 시작)
- LR 파서 : 상향식 파서 (Terminal부터 시작)


- LR(1) 파서
- 이동 축소 파싱(shift-reduce parsing) : Shift와 Reduce를 반복하여 파싱


티스토리 에디터 너무 구리다 ㅜㅜ
'스터디 노트 > 컴퓨터 과학 기초' 카테고리의 다른 글
| 컴퓨터과학 기초 > 05장 변수/정수/실수/문자열 (0) | 2022.04.02 |
|---|---|
| 컴퓨터과학 기초 > 03장 운영체제 - 메모리 (0) | 2021.11.24 |
| 컴퓨터과학 기초 > 02장 운영체제 - 프로세스와 스레드 (0) | 2021.11.24 |
| 컴퓨터과학 기초 > 01장 CPU (0) | 2021.11.16 |
Python 기초 > 자료형 Unit1-1 숫자형
2021. 12. 9. 21:21
숫자형
print(1+1) # 2 : 더하기
print(3-2) # 1 : 빼기
print(5*2) # 10 : 곱하기
print(6/3) # 2 : 나누기
print(2**3) # 2^3 = 3 : 제곱
print(5%3) # 2 : 나머지 구하기
print(5//3) # 1 : 몫 구하기
print(1 > 3) # False
print(4 <= 4) # True
print(5 > 4 > 3) # True
print(3 == 3) # True : 똑같은지
print(1 != 3) # True : 다른지
print(not (1 != 3)) # 이중부정
print((3 > 0) and (3 < 5))
print((3 > 0) & (3 < 5)) # and
print((3 > 0) or (3 < 5))
print((3 > 0) | (3 < 5)) # or
+= : 계산한 값을 원래 값에 할당함
- [ i += 1 ] = [ i = i+1 ]
print(abs(-5)) # 5 : 절댓값
print(pow(4, 2)) # 4^2
print(max(5, 12)) # 12 : 최댓값
print(min(5, 12)) # 5 : 최솟값
print(round(3.14)) # 4 : 반올림
파이썬의 math 라이브러리
from math import *
print(floor(4.99)) # 4 : 내림
print(ceil(3.14)) # 4 : 올림
print(sqrt(16)) # 4 : 제곱근
랜덤함수
from random import *
print(random()) # 0.0 ~ 1.0 미만의 임의의 값 생성
print(random() * 10) # 0.0 ~ 10.0 미만의 임의의 값 생성
print(int(random() * 10)) # 0 ~ 10 미만의 임의의 값 생성
print(int(random()* 10) + 1) # 1 ~ 10 이하의 임의의 값 생성
print(randrange(1, 45)) # 1 ~ 45 미만 범위의 임의의 값 생성
print(randint(1, 45)) # 1 ~ 45 이하 범위의 임의의 값 생성
'스터디 노트 > Python 기초' 카테고리의 다른 글
| Python 기초 > 자료형 Unit1-2 문자열 자료형 (0) | 2022.06.11 |
|---|
C언어 기초 > 10장 동적 메모리 할당
2021. 12. 7. 21:39
메모리 할당
- 어떤 메모리 공간을 임의로 사용할 수 있도록 주는 것
int a = 0;
// a라는 변수가 임의의 메모리 공간을 int형만큼 할당을 받음
정적 메모리 할당
- 선언과 동시에 크기가 정해지고, 중간에 바꿀 수 없다.
- 소멸할 때 운영체제가 자동으로 할당한 메모리를 회수
int a;
char str[10];
int score[20][20];
동적 메모리 할당이 필요한 이유
char name[3][20] = {'김솔원', '김솔투', '김솔쓰리'}
// 실제 변수에 저장한 이름이 짧으면 공간 낭비임동적 메모리 할당
- 메모리가 허용하는 범위 내에서 원하는 만큼 메모리를 할당 받아 사용하고, 그 크기를 중간에 얼마든지 바꿀 수 있음
- 동적 메모리 할당의 과정
- 포인터 변수 선언
- 임의의 공간을 원하는 만큼 할당 받고, 그 주소를 포인터에 저장
- 포인터를 가지고 할당받은 메모리 공간 사용
- 필수 다 쓰면 할당받은 메모리를 해제하여 운영체제에 돌려줌 (안 하면 프로그램이 사용할 메모리 공간을 잃어버림
- 2~4번을 반복하면 한 개의 포인터를 가지고 할당 받는 메모리의 크기를 자유롭게 바꿀 수 있음
#include <stdio.h>
#include <stdib.h> // 관련 함수가 포함된 헤더 파일 포함
void main(){
char *str = NULL;
// 1. 포인터 변수 선언
str = (char*) malloc(20);
// 2. 임의의 공간을 원하는 만큼 할당받고, 그 주소를 포인터에 저장
// 포인터를 받을 변수 = (그 변수의 자료형) malloc(할당받을 바이트 수)
strcpy(str, "안녕하세요");
printf("%s/n", str);
// 3. 포인터를 가지고 할당받은 메모리 공간 사용
free(str);
// 4. 할당된 메모리 해제
}
// 또 다른 예제
int *p = (int*) malloc(sizeof(int) * 3);
p[0] = 1;
p[1] = 2;
p[2] = 3;
printf("%d\\t%d\\t%d\\n", p[0], p[1], p[2]);
free(p);
다중 포인터의 동적 메모리 할당
- 동적 메모리 할당은 2차원 배열, 2차원 포인터 등과 같이 다중포인터를 사용하는 것이 가능
#include <stdlib.h>
#include <string.h> // strcpy
int main(){
char **str = (char**) malloc(sizeof(char*)*3);
// 이중 포인터 str을 선언하고, 거기에 동적 메모리 할당으로 char형 포인터를 3개만큼 할당
str[0] = (char*) malloc(sizeof(char)*5);
str[1] = (char*) malloc(sizeof(char)*4);
str[2] = (char*) malloc(sizeof(char)*3);
// 각각의 포인터 배열의 원소들에 동적 메모리 할당
// 각 원소의 크기는 일반 2차원 배열과 달리 매우 자유롭게 지정할 수 있음
strcpy(str[0], "abcd");
strcpy(str[1], "efg");
strcpy(str[2], "hi");
// 지정된 크기 안에서 배열처럼 사용
free(str[0]);
free(str[1]);
free(str[2]);
free(str);
// 안쪽 원소부터 해제
return 0;
}

유용한 메모리 관련 함수들
memset
- 포인터가 가리키는 주소부터 바이트 수만큼을 값으로 채움
- 동적 메모리 할당 받은 str 전체를 바로 0으로 초기화!
memset(포인터, 값, 바이트수);
char *str = (char*) malloc(sizeof(char)*10);
memset(str, 0, sizeof(str));
memcpy
- 받을 포인터에 복사할 값이 들어 있는 주소부터 시작해서 바이트 수만큼 복사
memcpy(받을 포인터, 복사할 값이 들어있는 주소, 바이트수);
/*--- 예제 001 ---*/
char str[20] = "안녕하세요";
char str2[20];
memcpy(str2, str, sizeof(str));
strcpy(str2, str);
// 문자형 배열을 복사하는 데에는 strcpy가 더 편함
/*--- 예제 002 ---*/
char str[3][20] = {"안녕하세요", "반가워요", "안녕히가세요");
char str2[3][20];
memcpy(str2, str, sizeof(str));
// 2차원 배열을 복사하는 경우, strcpy보다 memcpy가 편함 (한 줄로 처리 가능)
'스터디 노트 > C언어 기초' 카테고리의 다른 글
| C언어 기초 > 09장 구조체 (0) | 2021.12.06 |
|---|---|
| C언어 기초 > 08강 포인터 (0) | 2021.12.05 |
| C언어 기초 > 07장 배열과 문자열 (0) | 2021.12.04 |
| C언어 기초 > 06장 함수 (0) | 2021.12.03 |
| C언어 기초 > 05장 조건문 (0) | 2021.12.02 |
C언어 기초 > 09장 구조체
2021. 12. 6. 20:24
구조체의 형태
struct 구조체 이름 { 구조체 멤버들 };
-----------------
자료형 부분
구조체의 예시
struct student
{
char name[15];
int s_id;
int age;
char phone_number[14];
};
int main()
{
**struct student goorm**;
printf("이름 : %s, 학번 : %d, 나이 : %d, 번호 : %s\\n", goorm.name, goorm.s_id, goorm.age, goorm.phone_number);
return 0;
}
구조체 초기화
.변수명 = 00
#include <stdio.h>
struct student
{
int age;
char phone_number[14];
int s_id;
};
int main()
{
struct student goorm = { **.age = 20**, **.phone_number = "010-1234-5678"**, 10 };
printf("나이 : %d, 번호 : %s, 학번 : %d\\n", goorm.age, goorm.phone_number, goorm.s_id);
return 0;
}
typedef를 이용한 구조체 선언
- typedef : C언어에서 자료형을 새롭게 이름 붙일 때 쓰는 키워드
- 구조체를 정의할 때 중괄호 뒤에 별칭을 써주면 됨
#include <stdio.h>
typedef struct _Student {
int age;
char phone_number[14];
} **Student;**
int main(){
**Student goorm; // struct student gorrm 이라고 할 필요 없이 별칭만 씀**
printf("나이 : ");
scanf("%d", &goorm.age);
printf("번호 : ");
scanf("%s", goorm.phone_number);
printf("----\\n나이 : %d\\n번호 : %s\\n----", goorm.age, goorm.phone_number);
return 0;
}
익명 구조체
#include <stdio.h>
typedef struct { **// 구조체 이름을 적지 않고 별칭만 사용**
int age;
char phone_number[14];
} Student;
int main(){
**Student goorm;**
printf("나이 : ");
scanf("%d", &goorm.age);
printf("번호 : ");
scanf("%s", goorm.phone_number);
printf("----\\n나이 : %d\\n번호 : %s\\n----", goorm.age, goorm.phone_number);
return 0;
}
구조체 배열
#include <stdio.h>
typedef struct {
char name[30];
int age;
} Student;
int main(){
Student goorm[3] = { {.name = "해리 포터"}, {.name = "헤르미온느 그레인저"}, {.name = "론 위즐리"} };
**// 문자열은 선언할 때만 초기화할 수 있으므로, 문자열은 선언과 동시에 초기화 필요**
goorm[0].age = 10;
goorm[1].age = 10;
goorm[2].age = 10;
printf("이름 : %s / 나이 : %d\\n", goorm[0].name, goorm[0].age);
printf("이름 : %s / 나이 : %d\\n", goorm[1].name, goorm[1].age);
printf("이름 : %s / 나이 : %d\\n", goorm[2].name, goorm[2].age);
return 0;
}
구조체 포인터
- 구조체를 가리키는 포인터
- 포인터를 사용할 때 *ptr.age 라고 하는 게 아니라, (*ptr).age 와 같이 괄호 사용 필요 (온점도 연산자이기 때문)
- ptr -> 변수 이렇게 써도 됨!
#include <stdio.h>
typedef struct {
int s_id;
int age;
} Student;
int main(){
Student goorm;
**Student *ptr;** **// 구조체를 가리키는 포인터**
ptr = &goorm;
**(*ptr).age = 20;**
**ptr->age = 20; // 이런 기호를 쓸 수도 있음**
**printf("goorm의 나이: %d\\n", goorm.age);
}
중첩 구조체
- 상위구조체 안의 하위구조체를 사용하고 싶으면 상위구조체.하위구조체.변수 와 같이 연속으로 멤버를 참조해야 함
- 담임 선생님의 정보를 학생 정보마다 넣고 싶을 경우, 학생 구조체 안에 선생님 구조체를 넣으면 편함
#include <stdio.h>
typedef struct {
char name[15];
int age;
} Teacher;
typedef struct {
char name[15];
int age;
**Teacher teacher;**
} Student;
int main(){
Student Student;
Teacher Teacher;
**Student.teacher.age** = 30;
Teacher.age = 40;
return 0;
}
자기 참조 구조체
- 자기 자신을 가리키는 포인터를 멤버로 가짐
- 나중에... 연결 리스트나 트리를 만들 때 쓰임 (자료구조)
typedef struct {
char name[15];
int age;
**struct Student *ptr;**
} Student;
구조체 전달
- 구조체는 값을 바꿀 필요가 없는 경우에도, 매개변수로 구조체를 전달할 때에는 포인터를 사용 (공간 세이브를 위해)
#include <stdio.h>
typedef struct {
int s_id;
int age;
} Student;
void print_student(Student *s){
s->s_id = 2000;
s->age = 25;
printf("학번 : %d, 나이 : %d\\n", s->s_id, s->age);
}
int main(){
Student s;
s.s_id = 1000;
s.age = 20;
print_student(&s);
printf("학번 : %d, 나이: %d\\n", s.s_id, s.age);
}
'스터디 노트 > C언어 기초' 카테고리의 다른 글
| C언어 기초 > 10장 동적 메모리 할당 (0) | 2021.12.07 |
|---|---|
| C언어 기초 > 08강 포인터 (0) | 2021.12.05 |
| C언어 기초 > 07장 배열과 문자열 (0) | 2021.12.04 |
| C언어 기초 > 06장 함수 (0) | 2021.12.03 |
| C언어 기초 > 05장 조건문 (0) | 2021.12.02 |
C언어 기초 > 08강 포인터
2021. 12. 5. 11:38
1. 포인터
💡 자료형 *변수명
리마인드
- * : 주소로 가서 값을 가져와라
- & : 주소가 뭔지 불러와라
- *& : 서로 상쇄 (아무것도 없는 거라고 생각)
포인터의 특징
- 기본 설명
void main() { int* p = NULL; int num = 15; p = # printf("포인터 p의 값 : %d \\n", p); // 93929524 printf("int 변수 num의 주소 : %d \\n", &num); // 93929524 printf("%d\\n", num); // 15 printf("%d\\n", *p); // 15 : *p = num의 주소 }
- 변수/클래스/스트럭쳐의 주소값을 저장하는 변수
- 그대로 불러오면 용량이 크므로 링크 따는 것, 포인터로 원본을 변경할 수 있음 (연산 가능)
- 포인터 변수의 크기는 모두 동일하지만, 자료형을 선언하는 이유는 가리킬 주소가 어떤 자료형을 갖는지 알려주기 위함 (가리키는 변수에 맞춰 포인터 변수도 자료형을 맞추면 됨)
- 포인터는 무조건 NULL(0)으로 초기화, 아니면 바로 주소값 넣기
- 연산자의 우선순위 : 참조 연산자(*)가 증감연산자(++, --)보다 순위가 높음
-
void main() { int *p = NULL; int num = 15; p = # printf("포인터 p가 가리키는 값 : %d\\n", *p); // 15 printf("num의 값 : %d\\n\\n", num); // 15 *p += 5; printf("포인터 p가 가리키는 값 : %d\\n", *p); // 20 : *p(num) + 5 printf("num 값 : %d\\n\\n", num); // 20 : 위 값이 num에 들어감 (*p)++; printf("포인터 p가 가리키는 값 : %d\\n", *p); // 21 : *p(num) + 1 printf("num 값 : %d\\n\\n", num); // 21 : 위 값이 num에 들어감 *p++; printf("포인터 p가 가리키는 값 : %d\\n", *p); // -13545343 : 주소를 찾아가지 않고 주소값이 들어있는 변수 p를 증가, 쓰레기값 출력 printf("num 값 : %d\\n", num); // 21 }
-
- 함수에서는 인자를 전달할 때 복사해서 사용하므로 전달해주는 원래 변수는 함수에서 수정 불가(call by value 어쩌구 개념 등장), 이때 포인터로 메모리의 주소를 넘겨주면 변수 값을 바로 수정 가능
-
void pointerPlus(int *num) { *num += 5; } void numPlus(int num) { num += 5; } void main() { int num = 15; printf("num 값 : %d\\n", num); numPlus(num); printf("numPlus 사용 후 : %d\\n", num); // 15 pointerPlus(&num); printf("pointerPlus 사용 후 : %d\\n", num); // 20 }
-
상수 포인터
- 포인터가 가리키는 변수를 상수화 (포인터를 통해 값 변경 불가)
-
void main() { int num = 10; const int* ptr = # }
-
- 포인터를 상수화 (주소값 변경 불가)
-
void main() { int num = 10; int *const ptr = # }
-
- 둘 다 상수화
-
void main() { int num = 10; const int *const ptr = # }
-
2. 포인터와 함수
Call by Value
- C언어에서 지원하는 방식
- 함수에서 값을 복사해서 전달하는 방식, 인자로 전달되는 변수를 함수의 매개변수에 복사 (인자로 전달한 변수와는 별개의 변수가 되기 때문에 원본 값이 바뀌지 않음, Swap 코드 참고)
- Swap 코드 예시
-
void swap(int a, int b) { int temp; temp = a; a = b; b = temp; } void main() { int a, b; a = 10; b = 20; printf("swap 전 : %d %d\\n", a, b); // 10 20 swap(a, b); printf("swap 후 : %d %d\\n", a, b); // 10 20 }
-
Call by Reference
- C언어에서는 공식적으로 지원하지 않으므로, Call by Address(주소값을 복사해서 넘겨주기)를 이용해야 함
- 함수에서 값을 전달하는 대신 주소값을 전달하는 방식
- Swap 코드 예시
-
void swap(**int *a, int *b**) { int temp; **temp = *a; *a = *b; *b = temp;** } void main() { int a, b; a = 10; b = 20; printf("swap 전 : %d %d\\n", a, b); // 10 20 **swap(&a, &b)**; printf("swap 후 : %d %d\\n", a, b); // 20 10 }
-
3. 포인터와 배열
- 다시 한번 리마인드
- * : 주소로 가서 값을 가져와라
- & : 주소가 뭔지 불러와라
- *& : 서로 상쇄 (아무것도 없는 거라고 생각)
특징
- 배열의 이름은 주소값 (포인터 변수의 값)
- 포인터 주소에 증가 연산을 하는 경우, 자료형의 크기 x N만큼 증가함
- *(arr+i) == arr[i]
- type형 포인터를 대상으로 n 크기만큼 값을 변경시키면 n x sizeof(type) 크기만큼 값이 증가/감소한다. (int 형일 경우 4씩, double 형일 경우 8...) 그래서 위와 같이 배열일 경우 *(arr+i) == arr[i] 가 성립
- 특징 총정리
void main()
{
int arr[5] = { 10, 20, 30, 40, 50 }; // 배열 (이름, 주소) : arr (10, 00000024)
int* arrPt = arr; // 포인터 : 00000024
// 배열의 [이름]은 [배열의 첫번째 값]과 동일
printf("%d\\n", *arrPt); // 10
printf("%d\\n", arr[0]); // 10
// 배열[i] = 포인터[i]
printf("%d\\n", arrPt[0]); // 10
printf("%d\\n", arrPt[1]); // 20
// 포인터(배열주소)에 숫자를 더하면 : (자료형의 크기 x n)
printf("%d\\n", arrPt); // 00000024
printf("%d\\n", arrPt + 1); // 00000028
// 배열에 숫자를 더하면 : 배열 주소에 숫자를 더한 것과 동일
printf("%d\\n", arr); // 00000024
printf("%d\\n", arr + 1); // 00000028
// 포인터(배열주소)에 숫자 더한 후 값을 가져오기
printf("%d\\n", *(arr + 1)); // 20 = arr[1]
printf("%d\\n", *(arr + 2)); // 30 = arr[2]
// 배열 각 인덱스의 주소값
printf("%d\\n", &(arr[0])); // 00000024
printf("%d\\n", &(arr[1])); // 00000028
// 따라서 : ***(arr+i) == arr[i]**
}
- 함수 인자로 배열 전달할 때 배열의 크기를 sizeof로 전달
-
**void 함수(int *arr, int len)** { for (int i=0; i < len; i++) printf("%d\\n", arr[i]); } void main() { int arr[10] = {1, 2, 3, 4, 5}; **함수(arr, sizeof(arr) / sizeof(int));** }
-
- 연습문제 : 포인터로 버블 정렬 함수 만들기
-
#include <stdio.h> void bubbleSort(int* arr, int len) { int temp; for (int i = 0; i < len-1; i++) { for (int j = 0; j < len-1; j++) { if (*(arr + j) > *(arr + j + 1)) { temp = *(arr + j); *(arr + j) = *(arr + j + 1); *(arr + j + 1) = temp; } } } } int main() { int arr[10]; for (int i = 0; i < 10; i++) { scanf("%d", &arr[i]); } bubbleSort(arr, sizeof(arr) / sizeof(int)); for (int i = 0; i < 10; i++) { printf("%d ", arr[i]); } return 0; } // 10 5 8 2 9 1 4 6 11 15
-
4. 이중 포인터(더블 포인터)
💡 포인터 변수를 가리키는 또다른 포인터 변수
- 또 다시 한번 리마인드
- * : 주소로 가서 값을 가져와라
- & : 주소가 뭔지 불러와라
- *& : 서로 상쇄 (아무것도 없는 거라고 생각)
이중 포인터 선언과 사용
#include <stdio.h>
void main()
{
int num = 10;
int* ptr = #
int** dptr = &ptr;
printf("%d\\n", *dptr); // ptr의 주소
printf("%d\\n", *(*dptr)); // ptr이 가리키는 값 (num), = **dptr
}

#include <stdio.h>
int main()
{
int num = 10;
int* ptr = #
int** dptr = &ptr;
int* ptr2;
printf("%d %d\\n", num, &num); // 10, 10000024
printf("%d %d\\n", ptr, *ptr); // 10000024, 10 : num의 주소값, ptr(num)의 값
printf("%d %d %d\\n", dptr, *dptr, **dptr); // 10000012 10000024 10 : dptr의 주소값, prt의 주소값, ptr(num)의 값
ptr2 = *dptr; // ptr2에 ptr에 저장된 값을 넣음 (num의 주소)
*ptr = 20; // ptr(num)에 20을 넣음
printf("%d %d\\n", ptr2, *ptr2); // 10000024 20 : ptr의 주소값, ptr2(num)의 값
printf("%d %d\\n", num, **dptr); // 20 20 : num의 값, ptr(num)의 값
return 0;
}
포인터 변수 대상의 Call by Reference
- 함수를 이용해서 싱글 포인터 변수 값을 변경하는 경우, 같은 싱글 포인터 변수를 사용하면 값 변경하지 못함
- (ptr1, ptr2 자체의 주소가 넘어가는 게 아니라, 저장된 값(num의 주소)과 같은 주소값을 가진 변수 p1, p2가 새로 생겨나기 때문)
#include <stdio.h> void swapPtr(int* p1, int* p2) { int* tmp = p1; p1 = p2; p2 = tmp; } void main() { int num1 = 10, num2 = 20; int* ptr1, * ptr2; ptr1 = &num1, ptr2 = &num2; printf("*ptr1, *ptr2 : %d %d\\n", *ptr1, *ptr2); // 10 20 swapPtr(ptr1, ptr2); printf("*ptr1, *ptr2 : %d %d\\n", *ptr1, *ptr2); // 10 20 } - 호출되는 함수의 매개변수를 더블 포인터 변수로 바꾸고, 인자로 싱글 포인터 자체의 주소값을 넘겨야 값이 제대로 변환됨
-
#include <stdio.h> void swapPtr(int**p1, int**p2) // 더블 포인터 변수 선언 { int* tmp = *p1; *p1 = *p2; *p2 = tmp; } void main() { int num1 = 10, num2 = 20; int* ptr1, * ptr2; ptr1 = &num1, ptr2 = &num2; printf("*ptr1, *ptr2 : %d %d\\n", *ptr1, *ptr2); // 10 20 swapPtr(&ptr1, &ptr2); // 싱글 포인트 변수의 주소값을 함수의 인자로 사용 printf("*ptr1, *ptr2 : %d %d\\n", *ptr1, *ptr2); // 20 10 }
-
'스터디 노트 > C언어 기초' 카테고리의 다른 글
| C언어 기초 > 10장 동적 메모리 할당 (0) | 2021.12.07 |
|---|---|
| C언어 기초 > 09장 구조체 (0) | 2021.12.06 |
| C언어 기초 > 07장 배열과 문자열 (0) | 2021.12.04 |
| C언어 기초 > 06장 함수 (0) | 2021.12.03 |
| C언어 기초 > 05장 조건문 (0) | 2021.12.02 |
C언어 기초 > 07장 배열과 문자열
2021. 12. 4. 15:51
배열 (집합)
- 값을 초기화하지 않으면 쓰레기값이 들어감
- 배열 사용법
-
void main() { int arr[5] = {1, 33 , 47, 102, 155}; int arr[] = {1, 2, 3}; } -
void main() { // 여러 개의 변수를 동시에 선언 int subwayArray[3]; subwayArray[0] = 30; subwayArray[1] = 40; subwayArray[2] = 50; for (int i = 0; i < 3; i++) { printf("%d\n", subwayArray[i]); } }
-
- sizeof(배열명) : 배열의 크기를 숫자로 출력 (메모리 상에서 차지하고 있는 용량)
- sizeof를 응용해서 for문 돌리기
-
int main() { int arr[5] = { 1, 2, 3, 4, 5 }; **int length = sizeof(arr) / sizeof(int); // 자료형의 크기만큼 나눠 주기** printf("arr의 길이는 : %d\\n", length); for (int i = 0; i < length; i++) { printf("%d\\n", arr[i]); } return 0; }
-
- sizeof를 응용해서 for문 돌리기
배열 출력 예제~~~
char tmp[4] = { "aaa" }; // aaa0 (nul문자 포함)
char tmp[1] = { 'a' }; // a
문자열
- 아스키 코드/유니코드(숫자를 글자에 대응)로 문자 사용 가능
- %c로 출력
void main() { char ch = 'a'; printf("%d\\n", ch); // a 와 매칭되는 97 출력 printf("%c\\n", ch); // a 출력 } - 배열으로 문자열 나타내기
- %s 로 출력
- 선언할 때 바로 값을 넣어주어야 함, 선언을 한 후에 값을 넣고 싶을 때에는 ch[0] = 'a'; 이렇게 대입
- 종료 문자를 통해 어디까지 출력할 것인지 컴퓨터에게 알려주기
- 종료 문자 : 0, NULL, \0
void main() { char ch[7] = { 'a', 'b', 'c', 'd', 0, 'e', 'f' }; printf("ch 는 %s", ch); }
- 배열 입력받기
- 배열의 이름은 주소를 담고 있으므로, &를 쓰지 않고 변수 이름만 쓰면 됨
-
void main() { char ch[201]; printf("200 자 이내로 입력해주세요 : "); scanf("%s", ch); // & 표시 없이 scanf 입력 받기 printf("%s", ch); }
문자열 비교 함수 wcscmp
#include <stdio.h>
#include <string.h> // strcmp 함수가 선언된 헤더 파일
int main()
{
char s1[10] = "Hello";
char *s2 = "Hello";
int ret = strcmp(s1, s2); // 두 문자열이 같은지 문자열 비교
printf("%d\\n", ret); // 0: 두 문자열이 같으면 0
return 0;
}
'스터디 노트 > C언어 기초' 카테고리의 다른 글
| C언어 기초 > 09장 구조체 (0) | 2021.12.06 |
|---|---|
| C언어 기초 > 08강 포인터 (0) | 2021.12.05 |
| C언어 기초 > 06장 함수 (0) | 2021.12.03 |
| C언어 기초 > 05장 조건문 (0) | 2021.12.02 |
| C언어 기초 > 04장 반복문 (0) | 2021.12.01 |
C언어 기초 > 06장 함수
2021. 12. 3. 21:17
함수
- 특징
- 이게 바로 함수
-
#include <stdio.h> int sum(int x, int y) { return x + y; } void main() { int result = sum(1, 2); printf("%d\n", result); } - C는 절차지향언어이므로, 위에서 아래로 차례대로 함수를 작성해 줘야 함 (혹은 main 아래에서 사용했을 경우 위에서 선언해 주어야 함)
- 함수에서는 인자를 전달할 때 복사해서 사용함 (전달해주는 원래 변수는 함수에서 수정 불가, 이때 08. 포인터 로 메모리의 주소를 넘겨주면 변수 값을 바로 수정 가능
변수의 종류
- 지역변수 : 특정 함수 안에서만 쓸 수 있는 변수
- 전역변수와 지역변수의 이름이 같은 경우, 지역변수에 우선 접근
- 전역변수 : 어디서나 사용 가능
-
#include <stdio.h> int global = 10; void globalTest() { //여기서도 사용 가능 } int main() { //여기서도 사용 가능 }
-
'스터디 노트 > C언어 기초' 카테고리의 다른 글
| C언어 기초 > 08강 포인터 (0) | 2021.12.05 |
|---|---|
| C언어 기초 > 07장 배열과 문자열 (0) | 2021.12.04 |
| C언어 기초 > 05장 조건문 (0) | 2021.12.02 |
| C언어 기초 > 04장 반복문 (0) | 2021.12.01 |
| C언어 기초 > 03장 연산자 (0) | 2021.11.29 |